在数据爆炸式增长的时代,高效的数据处理与存储格式成为技术架构的关键。Apache Parquet作为一种开源的列式存储格式,凭借其卓越的性能与兼容性,已成为大数据生态系统中不可或缺的一环。本文将从核心原理、数据处理优势及存储支持服务三个维度,再次深入探讨Parquet的价值与应用。
一、Parquet列式存储的核心原理
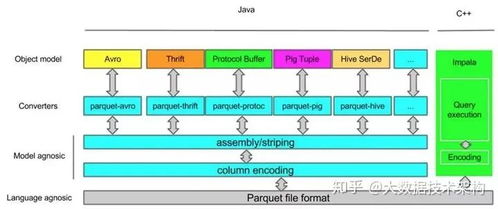
Parquet的设计哲学源于对传统行式存储的革新。与按行组织数据不同,Parquet将数据按列存储。每一列的数据被连续存放,并辅以丰富的元数据(如最小值、最大值、计数等)。这种结构结合了高效的压缩算法(如Snappy、GZIP)与精巧的编码方式(如字典编码、游程编码),使得存储空间大幅缩减,I/O效率显著提升。
二、数据处理中的显著优势
- 查询性能优化:对于分析型查询,通常只涉及部分列。Parquet的列式特性允许系统仅读取所需列的数据,避免了全表扫描,极大降低了I/O开销,加速了聚合、过滤等操作。
- 高效压缩与编码:同类数据集中存储,压缩率更高;结合谓词下推技术,可在读取前过滤无关数据,进一步提升处理速度。
- 模式演进支持:Parquet支持复杂的嵌套数据结构,并允许向后兼容的模式变更,方便数据模型的迭代。
- 跨平台兼容性:作为与语言和框架无关的格式,Parquet被Spark、Hive、Presto、Pandas等主流数据处理工具广泛支持,实现了生态无缝衔接。
三、存储支持服务与最佳实践
在云原生与混合架构背景下,Parquet的存储支持服务愈发重要:
- 云存储集成:Parquet文件可高效存储于AWS S3、Google Cloud Storage、Azure Blob Storage等对象存储中,结合生命周期策略与分层存储,优化成本。
- 数据湖/仓基石:在Delta Lake、Apache Iceberg等表格格式中,Parquet常作为底层存储格式,提供ACID事务与时间旅行功能。
- 优化建议:
- 合理设置行组大小(通常128MB-1GB),平衡I/O效率与内存使用。
- 根据数据特征选择压缩编码,如高基数列适用字典编码。
- 利用分区与排序策略,将相关数据集中,最大化查询性能。
###
Parquet不仅是一种存储格式,更是现代数据架构的核心组件。其列式设计深刻契合了分析型负载的需求,而广泛的生态支持与云服务集成,使其成为数据处理管道中可靠且高效的选择。随着数据体量与复杂度的持续增长,深入理解并合理应用Parquet,将为数据平台的建设与优化奠定坚实基础。