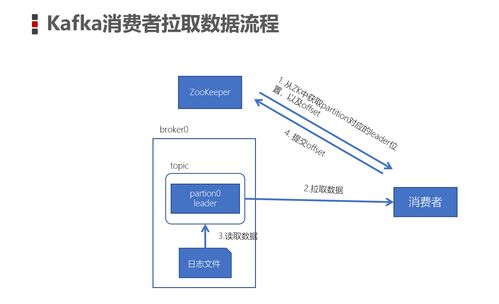
Kafka作为高吞吐量的分布式消息系统,通过多重机制保障数据的完整性和可靠性。本文将从消息防丢失、消费模式、存储形式及支撑服务四个维度展开详细解析。
一、Kafka如何保证消息不丢失
- 生产者端保障机制
- 异步发送模式下启用回调确认
- 同步发送模式设置acks=all/-1(需所有ISR副本确认)
- 配置retries参数实现自动重试
- 设置max.in.flight.requests.per.connection=1保证顺序重试
- Broker端持久化策略
- 消息追加写入Commit Log文件
- 支持多副本机制(Replication)
- 采用ISR(In-Sync Replicas)同步副本列表
- 支持min.insync.replicas配置最低同步副本数
- 消费者端确认机制
- 启用手动提交offset(enable.auto.commit=false)
- 处理完消息后调用commitSync()同步提交
- 配合事务机制保证精确一次处理
二、Kafka消费数据模式
- 消费者组模式(Consumer Group)
- 同一分组内消费者平均分配分区
- 支持水平扩展和负载均衡
- 实现"一个分区只被一个消费者消费"
- 独立消费者模式
- 直接指定消费的分区
- 适用于特殊场景的定点消费
- 两种订阅方式
- 主题订阅(subscribe):动态分区分配
- 分区分配(assign):静态指定分区
三、Kafka的数据存储形式
- 分区日志结构
- 每个分区对应一个物理文件夹
- 采用顺序追加写入方式
- 通过分段(Segment)机制管理文件
- 索引文件设计
- .index文件:存储offset到物理位置的映射
- .timeindex文件:支持按时间戳查找
- 采用稀疏索引提升查询效率
- 数据清理策略
- 基于时间的保留策略(log.retention.hours)
- 基于大小的保留策略(log.retention.bytes)
- 支持日志压缩(Log Compaction)去除重复键
四、数据处理和存储支持服务
- Connect框架
- 提供标准化数据导入导出接口
- 支持与关系数据库、HDFS等系统集成
- 内置多种Connector实现
- Streams API
- 实现实时流处理功能
- 支持状态管理、窗口操作
- 提供Exactly-Once语义保障
- 监控与管理工具
- Kafka Manager可视化管控平台
- 内置Metric指标收集
- 支持JMX监控接口
- 集群协调服务
- 依赖ZooKeeper维护元数据
- 管理Broker注册、主题配置
- 协调消费者组Rebalance操作
通过上述机制的协同工作,Kafka构建了一套完整的数据可靠性保障体系,在保证高性能的提供了企业级的数据持久化和处理能力。